Web Testing - Using XPath Queries¶
Purpose¶
When testing web applications, you will explicitly or implicitly use XPath expressions to query the browser's DOM for elements based on the scenario under test. This section explains how XPath queries are used in Rapise and how to make your browser testing more flexible and adaptive to changes in the application under test.
XPath Fundamentals¶
XPath uses path expressions to select nodes in an XML document such as HTML. A node is selected by following a path or steps.
Refer to XPath Tutorial for more details.
Rapise XPath Extensions¶
Frames¶
Web pages sometimes use HTML frames. XPath works on the content within a frame. Rapise has a special syntax (that is not part of standard XPath) to combine multiple locators into a single line:
//frame[@name='main']@@@//a[3]
The special @@@ string is used as a separator to combine locators for frames and the elements within them.
The top-level frame is found by its name, main:
//frame[@name='main']
Then, the frame's content is searched for the <a> element that is the 3rd child of its parent element.
//a[3]
Note
Segments of a locator separated by @@@ can be either XPath or CSS. For example, the following locators are equivalent:
1 2 3 4 | |
Shadow DOM¶
Another XPath extension is related to Shadow DOM. Its borders are typically closed to XPath. In such cases, a locator for an element inside a Shadow DOM has two parts separated by the @#@ delimiter. The first part (which can be XPath or CSS) must point to the Shadow Root in the Light DOM. The second part (which is always CSS) must point to a child element of the Shadow Root. In the case of nested Shadow DOMs, there will be multiple @#@ delimiters.
Example of a locator:
automatically built by WebSpy
/html/body[1]/section[1]/div/guid-generator[1]@#@css=input:first-of-type
//guid-generator@#@css=input
Find an example of a simple page with a Shadow DOM on UI Testing Playground.
Piercing Shadow DOM¶
Rapise 8.2+ can pierce the Shadow DOM. This means that if a CSS selector does not use the @#@ delimiter described above, Rapise will search for an element without regard to Shadow DOM boundaries.
For example, on this page:
<section>
<div>
<guid-generator>
# shadow-root (open)
<input class="edit-field" id="editField">
<button class="button-generate" id="buttonGenerate"><i class="fa fa-cog"></i></button>
<button class="button-copy" id="buttonCopy"><i class="fa fa-clone"></i></button>
</guid-generator>
</div>
</section>
we can find the <input> element with:
css=input
css=input[id='editField']
css=guid-generator input
css=guid-generator > input
Note
The Shadow DOM piercing feature may break existing tests, as previously recorded locators may start to find additional elements. In this case, make your locators more specific.
Automatic XPath Generation on Record and Learn¶
When you start a recording session, interact with web elements, or learn them, Rapise generates XPath locators for them. You can view the XPath of an object in the property grid:
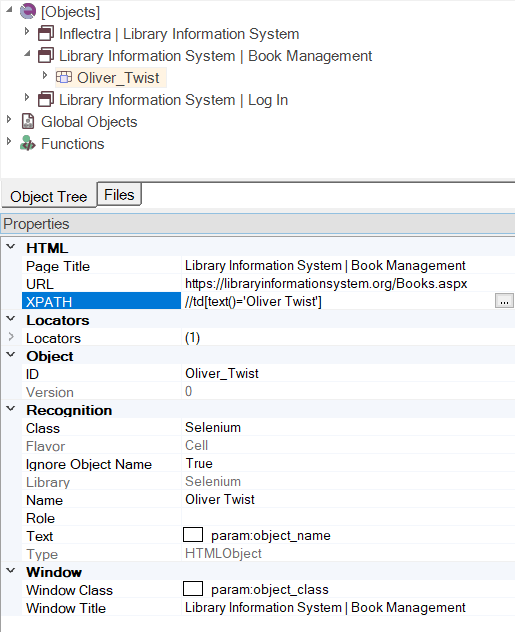
Usage¶
In Web Spy¶
In some advanced cases, you may need to construct an XPath query manually. For this purpose, we recommend using the Web Spy tool:

If you enter an XPath query at the top and click Test, Rapise will display all the DOM elements that match the query:
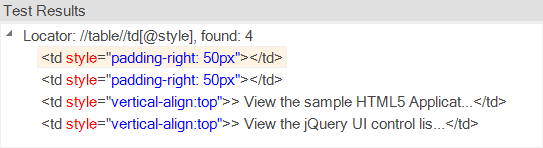
You can now refine the query to find only the item you want to test.
When you have created a query in Web Spy that returns the expected HTML element, you can click the Learn button in the Web Spy toolbar to learn that element. This creates a new Rapise object in the Object Tree that maps to this specific XPath.
For example, to find a specific book in a grid of books:
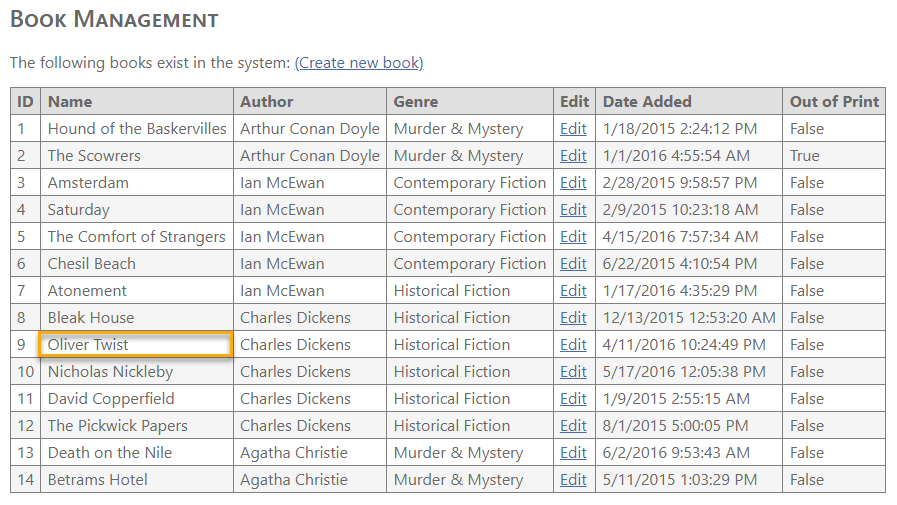
you can search by its name using the text() XPath function:
//td[text()='Oliver Twist']
Then, learn this object as Oliver_Twist so that you can access it in your code as SeS("Oliver_Twist"). Every time you call a function on Oliver_Twist, Rapise uses the learned XPath expression to find the corresponding HTML element on the web page.
Dynamic Queries¶
In addition to learning objects based on a specific XPath, you can use the HTMLObject.DoDOMQueryXPath action to query for elements on the web page:
var res = SeS('MainContent_grdBooks').DoDOMQueryXPath('.//td[text()="Oliver Twist"]');
Tester.Message(res.length);
This action dynamically queries for any HTML element that is a child of the learned MainContent_grdBooks object and matches the specified XPath. In this example, it looks for any table cell containing the book's name.
You can also find an object dynamically without having an object in the Object Tree. To do this, use the Navigator.SeSFind action.