Web Spy Settings Dialog¶
Purpose¶
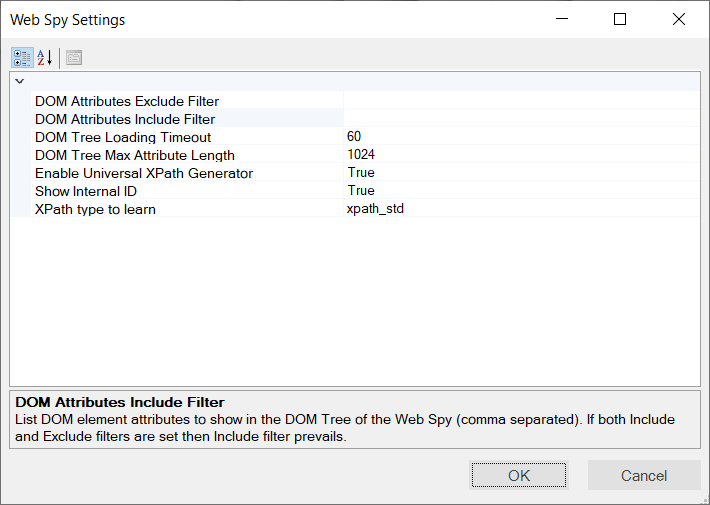
This dialog box displays the Web Spy settings and allows you to change the behavior of the Web Spy tool.
How to Open¶
You can open this dialog box from two places:
- From the main Rapise menu
Settings > Web Spy. - From the Web Spy tool by clicking on the
Spy > Web Spy Settingsmenu item.
General Settings¶
This dialog box has the following settings:
- DOM Attributes Exclude Filter - A comma-separated list of DOM element attributes to hide in the Web Spy's DOM Tree.
- DOM Attributes Include Filter - A comma-separated list of DOM element attributes to show in the Web Spy's DOM Tree. If both Include and Exclude filters are set, the Include filter prevails.
- DOM Tree Loading Timeout - Allows you to extend or reduce the amount of time (in seconds) Rapise allows for loading the DOM Tree. This can be useful for slower web browsers and/or complex websites with many nested frames. The default value is 10 seconds.
- DOM Tree Max Attribute Length - Allows you to specify the maximum length of DOM attributes. The smaller the value, the faster the DOM tree will load. The default is 1024 characters.
- Enable Universal XPath Generator - When set to 'True', this option generates XPath and CSS selectors within Web Spy itself, rather than relying on the web browser for generation. This is usually much faster (especially when using Internet Explorer).
- Fast DOM Tree Build - If set to 'True', Rapise uses embedded code to retrieve the DOM Tree when using either the Internet Explorer HTML library or any of the Selenium libraries.
- Show Internal ID - If 'True', the DOM Element pane shows the internal ID of an element. This ID is internal to Rapise and is not part of the HTML web page or web application.
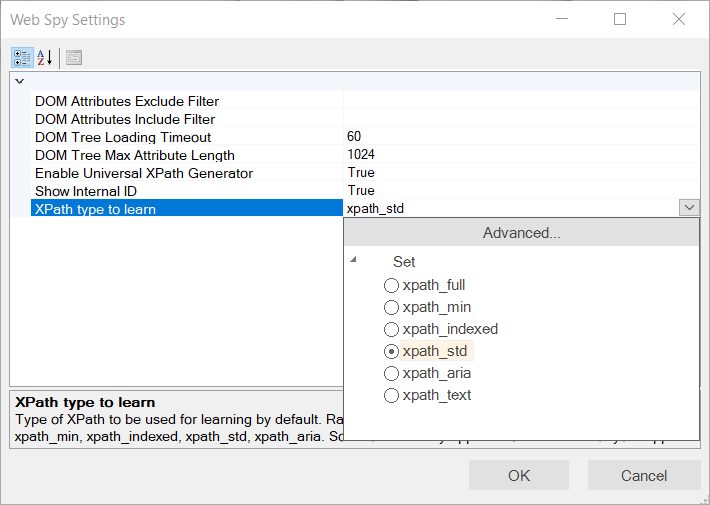
- XPath Type to Learn - This is described in the section below:
Different Types of XPath¶
Web Spy has a variety of options for XPath generation. Having a number of different approaches for generating XPath offers several benefits. This gives Rapise incredible flexibility in achieving the best results for different situations:
- Sometimes, an element can be recognized by its text. In such cases, the simplest and most efficient XPath uses the node text.
- For structures with a regular layout (tables and grids), it is better to include row and column indices within the XPath.
- When dealing with an application framework that uses custom attributes (e.g.,
aria,angular,bootstrap), using these custom attributes in the XPath results in a cleaner and more robust XPath.
The Web Spy currently supports the following different types of XPath:
- xpath_full - Generates a full XPath path using elements without attributes. This XPath starts with
/htmland traverses the<body>and other elements to the required node. -
xpath_min - Generated using the attributes defined in the DOM Attributes Include Filter. If the include filter is empty, it is generated with all attributes except those defined in the DOM Attributes Exclude Filter. For example, if the include filter contains the
widgetidcustom attribute, the generated XPath would be:1//div[@widgetid="dojox_grid__View_1"] -
xpath_indexed - Considers a node as the Nth instance of its kind. For example, if a page contains 250 <a href=…> links and you want to identify a link somewhere in the middle, the indexed XPath will be of the form
(//a)[123]. -
xpath_std - Generated and minimized using a pre-selected set of attributes:
- align
- class
- style
- size
- tabindex
- value
- width
- height
- colspan
- rowspan
- cellspacing
- cellpadding
- border
- on* (e.g.,
onclick,onblur, etc.)
It usually includes common attributes such as
id,name,for, androle. -
xpath_aria - Generated using only the core
idandnameattributes, plus the special ARIA attributes:- id
- name
- for
- role
- aria-*
- xpath_text - If possible, generated to match an HTML node simply by its text. For example,
<button>Refresh</button>is found using://button[normalize-space(text())="Refresh"]. In many cases, this value is empty. This typically means that multiple nodes share the same text.