Web Application Profile¶
Each web application is unique in how it assigns attributes to elements, which complicates the process of generating XPath locators. Some applications assign dynamic IDs to elements; some use ARIA attributes while others do not; and some class attribute values are meaningful for element positioning, while others are used purely for styling. There are also cases where an app contains hidden DOM layers that stack on top of each other. Therefore, using the same set of attributes for generating XPaths is not efficient and may lead to weak locators that break after an application reloads or undergoes slight modifications. To address these challenges, Rapise introduces the Web App Profile. It is a simple JSON file with a defined structure that instructs Rapise how to build XPaths for elements in a particular application. This topic explains how to define a profile for your web application.
Note
In some cases, Web Application Profile is also referred to as Web Recorder Configuration. These terms are synonyms.
Purpose of WebAppProfile¶
WebAppProfile serves as an instruction to Rapise on how to record XPath locators for elements in a given application.
WebAppProfile addresses one of the challenges in web UI test automation: the generation of resilient XPath locators during test recording.
Adding WebAppProfile to a Test¶
To create a WebAppProfile.json file in your test, navigate to the Files tab, right-click the Scripts folder, and choose Create... > WebAppProfile.json.
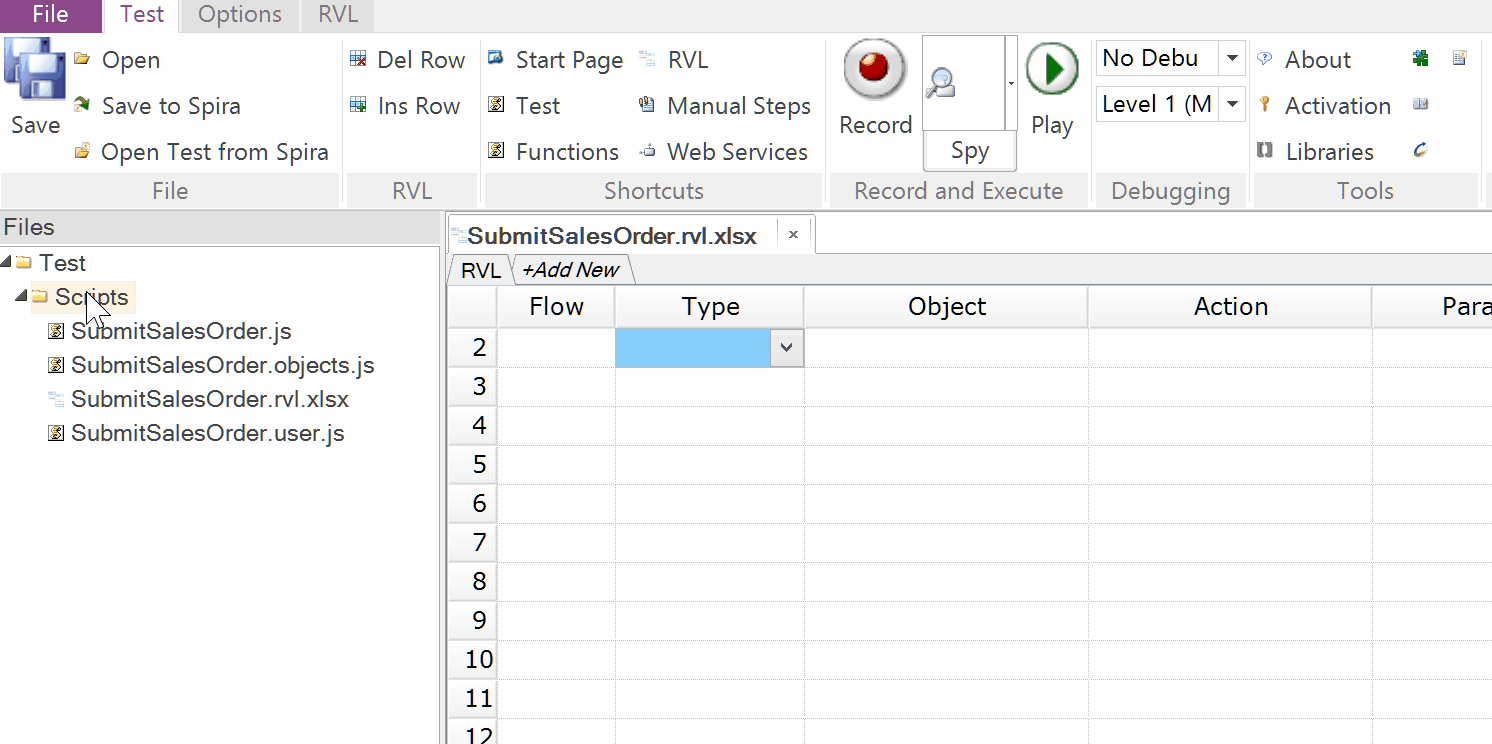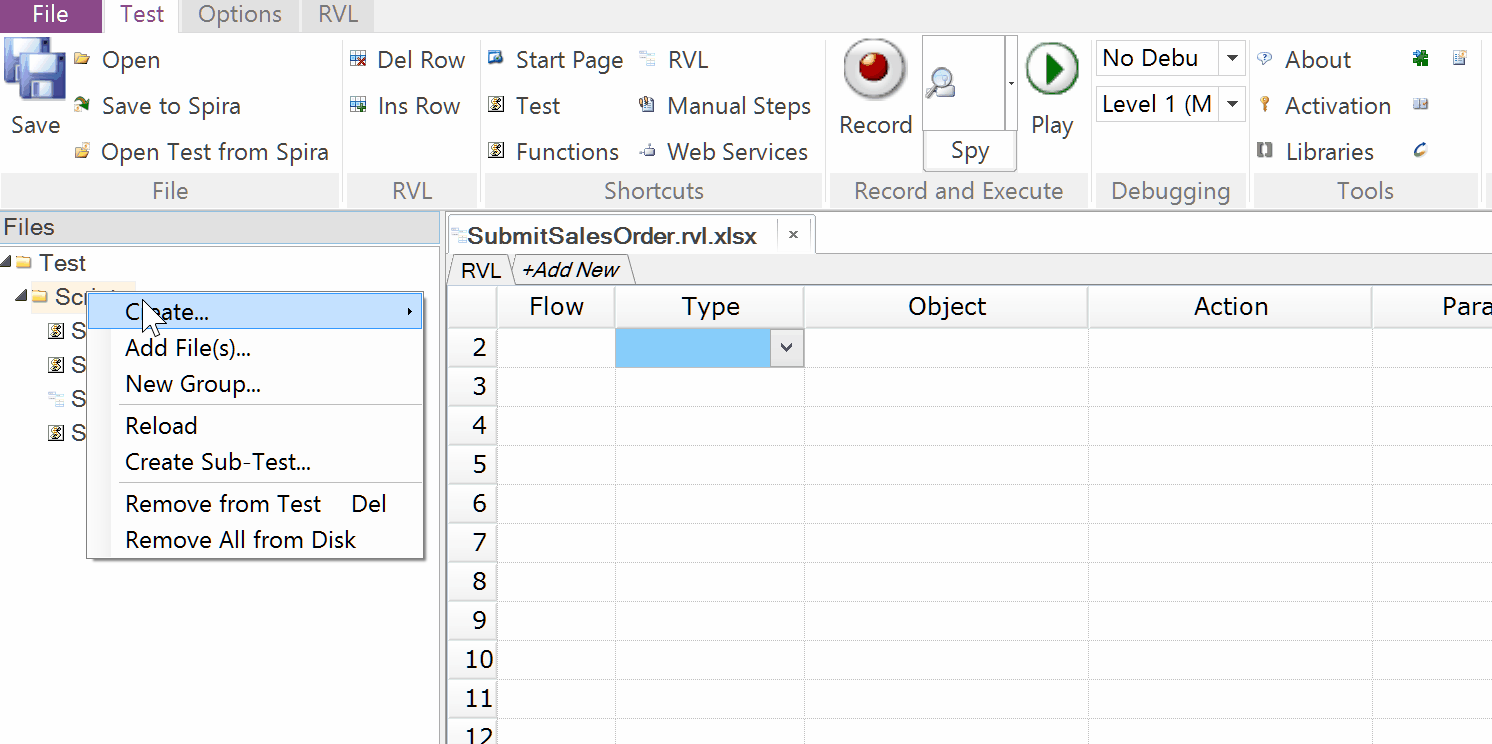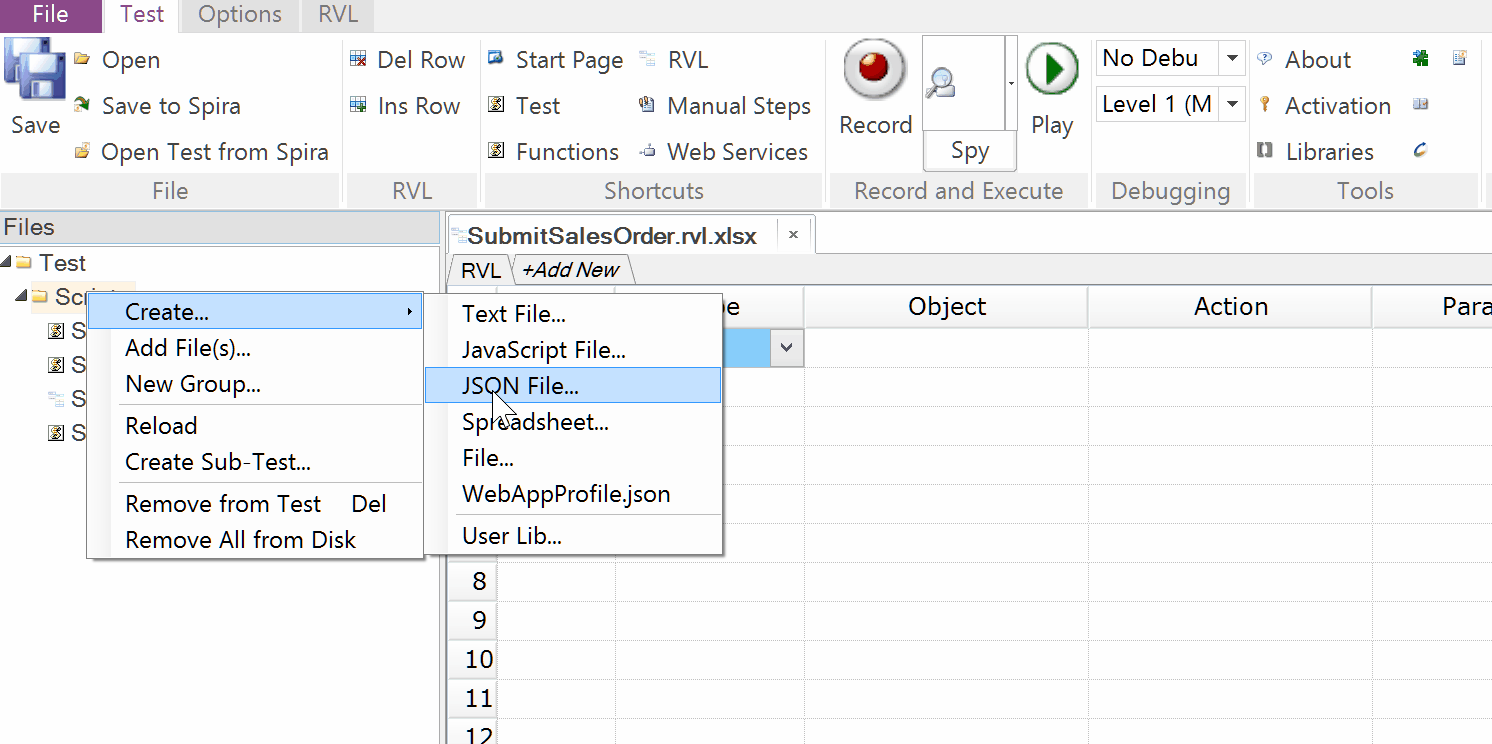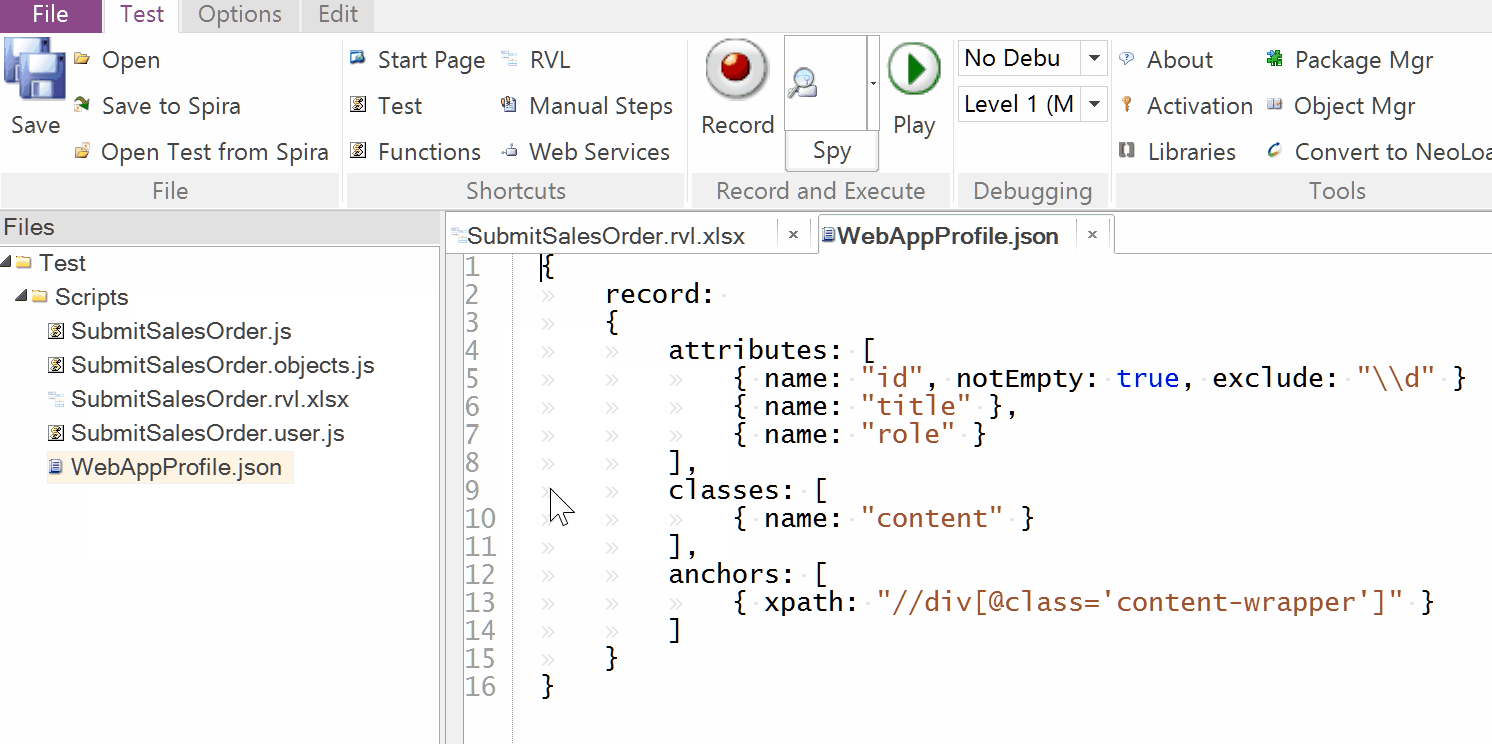
The default profile looks like this:
{
record:
{
attributes: [
{ name: "id", notEmpty: true, exclude: "\\d" },
{ name: "title" },
{ name: "name" },
{ name: "style" },
{ name: "type" },
{ name: "value" },
{ name: "placeholder" },
{ name: "autocomplete" },
{ name: "href" },
{ name: "role" }
],
classes: [
/* { name: "content" } */
],
anchors: [
/* { xpath: "//div[@class='content-wrapper']" } */
],
clickable: {
classes: [
/* "sapMInputBaseIcon" */
]
},
handlers:
{
elementName: function(el)
{
/*
var label = __getAttribute(el, "aria-label");
if (label)
{
if (label.indexOf(",") > 0)
{
return label.split(",")[0];
}
return label;
}
*/
return null;
},
skipAttribute: function (node, attr, value)
{
/*
var tag = node.tagName.toLowerCase();
if (attr == "title")
{
if (tag == "textarea" || tag == "select" || tag == "input")
{
return true;
}
}
else if (attr == "text")
{
if (__hasAttribute(node, "data-id") || __hasAttribute(node, "id"))
{
return true;
}
}
*/
return false;
},
clickable: function(el)
{
/*
var tag = el.tagName.toLowerCase();
if (tag == "p" || __hasAttribute(el, "title"))
{
return true;
}
*/
return false;
}
}
}
}
WebAppProfile Format¶
-
record.attributesarray contains the definition of attributes to record.nameis the only required property for an attribute. It is case insensitive.notEmptyisfalseby default. If set totrue, the attribute will be recorded only if it has a non-empty value.excludeis a regular expression. If an attribute's value matches the regexp, the attribute is not recorded.
Note: Rapise 6.4+ supports the
textattribute, which is mapped to the inner text of leaf elements. -
record.classesarray lists class names that are meaningful for element identification and should be recorded.nameis the only required property for a class. It is case sensitive.
record.anchorsarray lists anchors.xpathis the only required property for an anchor.
record.clickable.classesis an array of classes that indicate clickable elements. By default, Rapise does not record clicks on DIVs, SPANs, and some other elements. By listing classes of elements that can be clicked, you may change this default behavior. Requires Rapise 6.4+record.handlersis an object that defines functions injected into the recorder. Requires Rapise 6.4+elementName(el)builds a name for a given element. This name is used as the object ID in the object repository. If this function returnsnull, the default algorithm is used to build the name.skipAttribute(node, attr, value)allows skipping the recording of some attributes in specific cases. The function must returntrueif an attribute should not be recorded.clickable(el)provides fine-grained control over which element is considered clickable. When the function returnstrue, the element is considered clickable; iffalse, the default algorithm (determining if the element is clickable or not) is used. Requires Rapise 6.5+.
treatMouseUpAsClick, treatMouseDownAsClick¶
In rare cases where a web app interferes with the default mouse click processing mechanism, it may be necessary to set record.treatMouseUpAsClick or record.treatMouseDownAsClick to true. This will enable Rapise to record clicks that are processed by the application within MouseUp or MouseDown events.
Anchors¶
When an element's XPath is being recorded, and the element belongs to the sub-tree of an anchor element (including the anchor element itself), the element's XPath will either start with or be replaced by the anchor element's XPath.
Example 1¶
Let's look at an example. Here, we have a table built with DIVs and ARIA roles.
<div id="Customers" role="grid">
<div role="row">
<span role="cell" title="Contoso"></span>
...
</div>
...
</div>
If we record using just the title attribute, and its value is unique for the page, we'll end up with a locator:
//span[@title='Contoso']
However, if we define an anchor:
//div[@id='Customers']
we'll get the locator as:
//div[@id='Customers']//span[@title='Contoso']
The locator is now bound to the table. If another element with the Contoso title appears somewhere on the page (outside the table), we'll still find the correct element.
Example 2¶
Here is a more complex, real-life example. In the Microsoft Dynamics 365 Business Central application, when you navigate through forms, they are loaded into the DOM tree inside DIV elements with the spa-view class. When you move from one form to another, old forms are not unloaded and continue to stay in the DOM tree. They just have a lower z-index than the currently active form.

This means that when Rapise searches for an element during test playback, it should work with the topmost spa-view.
To achieve this goal, we define an anchor in the WebAppProfile for the application:
//div[contains(concat(' ', @class, ' '), ' spa-view ') and position()=last()]
Here is an example of automatically recorded XPath:
//div[contains(concat(' ', @class, ' '), ' spa-view ') and position()=last()]//span[@aria-label='Customers']
The anchor prevents finding elements that are not visible to the user and ensures that if an element is found, it belongs to an active form.
Example 3¶
Requires Rapise 6.4+. An anchor may be used to completely rewrite an element's XPath. This means if an anchor points to an element, it will be used instead of an XPath expression generated using attributes. Let's assume we have a page:
<table>
<tr>
<td>
<span>UserName</span>
</td>
<td>
<input type="text" id="obj-1267" title="Enter email or user ID:"/>
</td>
</tr>
</table>
If we have an anchor defined like:
{ xpath: "//input[../../td/span[text()='UserName']]"}
and we click on the field, then instead of something like:
//input[@title='Enter email or user ID:']
the recorder will use the anchor.
XPath Minimization¶
Rapise always tries to build the minimal XPath locator possible with a given set of attributes, classes, and anchors. Full XPath is not an option.
Let's assume we have a page:
<div>
<div>
<span title="Account"></span>
...
</div>
...
</div>
and XPath:
//span[@title='Account']
finds a single node, it is a good minimal locator for the element.
Compare with full XPath:
/div[1]/div[1]/span[@title='Account']
that may easily become broken with page layout changes.