Web Testing - Using CSS Selectors¶
Purpose¶
When testing web applications, you will often want to use Cascading Style Sheets (CSS) selectors to query the browser DOM for elements based on the scenario under test. This section explains how you can use CSS selectors with Rapise to make your browser testing more flexible and adaptive to changes on the screen.
CSS is an alternative to XPath that is often better at selecting multiple elements from across different parts of the DOM tree, unlike XPath, which is strictly hierarchical. However, since CSS is not always able to uniquely locate an object, when Rapise is used in recording mode, it will automatically learn objects using XPath.
CSS Fundamentals¶
In CSS, selectors are patterns used to select the element(s) you want to style. Here are the different operators that you can use in CSS selectors:
One limitation (compared to XPath) is that there is no way to select an element based on its content. For example, it would not be possible to locate a cell in a grid based on its content. For that, you would need to use XPath.
Rapise CSS Extensions¶
Prefix¶
Since Rapise uses XPath as its primary means of locating an HTML element, when you Learn an object using CSS, Rapise prefixes the Locator (listed under the XPath property for that object in the Object Tree) with css= to indicate that the locator is actually using a CSS selector.
css=html > body > form#ctl01 > div:nth-of-type(3) > div:first-of-type
Frames¶
Web pages sometimes use HTML frames. The CSS works inside the frame's content. Rapise has a special syntax (that is not part of standard CSS) to combine multiple CSS statements into a single line:
css=frame[name='main']@@@css=a:nth-of-type(3)
The special statement @@@ is used as a separator for CSS statements that point to constituent frames.
The top-level frame is found by the name main.
frame[name='main']
Then the frame's content is searched for the <a> element that is the third child of its parent element.
Note
Segments of a locator separated by @@@ can be both XPath and CSS. For example, the following locators are equivalent:
1 2 3 4 | |
Shadow DOM¶
Another CSS extension is related to Shadow DOM. Its borders are typically closed to CSS. In such a case, a locator for an element inside Shadow DOM has two parts, separated by the @#@ delimiter. The first part (can be XPath or CSS) should point to the Shadow Root in the Light DOM. The second part (always CSS) should point to a child element of the Shadow Root. In the case of nested Shadow DOMs, there will be multiple @#@ delimiters.
Example of a locator:
Automatically built by WebSpy
/html/body[1]/section[1]/div/guid-generator[1]@#@css=input:first-of-type
//guid-generator@#@css=input
css=guid-generator@#@css=input
You can find an example of a simple page with Shadow DOM on UI Testing Playground.
Usage¶
There are several different ways to use CSS selectors in Rapise.
In Web Spy¶
To most easily use CSS selectors in Rapise, we recommend using the Web Spy tool. Make sure that CSS editing is enabled:
If you enter the CSS selector at the top and then click Test

it will display all of the DOM elements that match the selector.
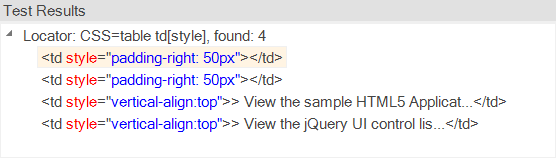
You can now refine the query to find only the items you want to test.
Learning Objects¶
Once you have created the query in the Web Spy that returns the HTML elements you expect, you can click the Learn button to learn that object. This will create a new Rapise object in the Object Tree that maps to this specific CSS selector. This means that the "object" in Rapise is effectively a pointer to this specific CSS selector.
For example, if you want to find a specific book in a grid of books by its CSS class, style, ID, or other attribute, you can search using the appropriate CSS selector, then learn this object as Book_1 so that you can access it in your code as SeS("Book_1"). Every time you call a function on Book_1, Rapise uses the learned CSS selector to evaluate which HTML element on the web page to access.
Dynamic Queries¶
In addition to learning objects based on specific CSS selectors, there is a set of general functions that can be used to query for objects on the web page:
SeS('Book_Management').DoDOMQueryCss('tr td[data=book1]');
This will dynamically query for any HTML element that is a child of the learned Book Management object and matches the CSS selector. In this example, it will look for any table cell in a table row that has the attribute data="book1".